Công nghệ đằng sau ChatGPT

ChatGPT là tiến bộ mới nhất trong lĩnh vực trí tuệ nhân tạo nói chung và xử lý ngôn ngữ tự nhiên nói riêng. Với sự "thông minh" đáng kinh ngạc của mình thì ChatGPT đang trở thành một đề tài rất thu hút và thú vị. Trong bài này, chúng ta sẽ tìm hiểu xem điều gì đã làm nên sự thành công của ChatGPT.
Large Language Models
Trước hết chúng ta cần phải biết ChatGPT về bản chất là một mô hình ngôn ngữ (language model), nhưng nó rất lớn, nên ta gọi đây là một large language model (LLM). ChatGPT là phiên bản cải tiến từ mô hình GPT-3, đây chỉ là một trong những mô hình ngôn ngữ rất lớn được xây dựng trong những năm gần đây. Ngoài GPT-3 ta còn các thế hệ trước của nó cũng được xây dựng và huấn luyện bởi OpenAI đó là GPT (2018), GPT-2 (2019) và có cả GPT-4 (dự kiến 2023). Ngoài ra còn có rất nhiều mô hình khác như BLOOM (BigScience, 2022), OPT (Microsoft, 2022), Megatron (NVIDIA, 2022),.. Tất cả các mô hình này đều có từ hàng tỷ đến hàng trăm tỷ tham số.
Về cơ bản, mô hình ngôn ngữ (language model) là dạng mô hình máy học có thể dự đoán xác suất của một câu hoặc một chuỗi ký tự trong ngôn ngữ tự nhiên. Nó được sử dụng rộng rãi trong nhiều tác vụ như tự động dịch, đề xuất từ và gợi ý câu.
Ví dụ, ta có một đoạn văn bản "Tôi sinh ra là để" thì mô hình ngôn ngữ sẽ giúp chúng ta tính được xác suất của từ tiếp theo trong câu như bên dưới.
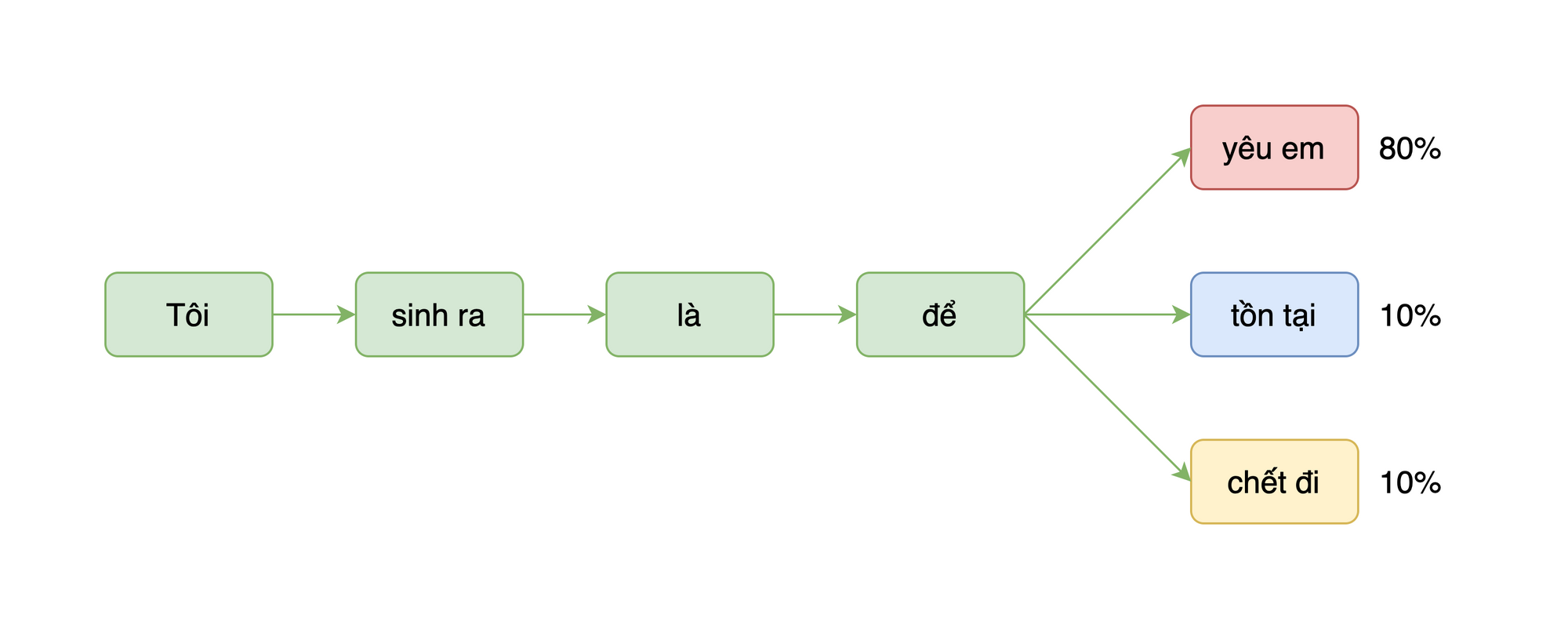
Ta có thể thấy xác suất để từ tiếp theo là "yêu em" là %80\%%, của "tồn tại" là %10\%% và của "chết đi" là %10\%%. Mô hình ngôn ngữ tính toán được các xác suất này bằng cách học từ các tập dữ liệu văn bản lớn và dựa trên tần suất của các từ và cấu trúc câu trong tập dữ liệu huấn luyện. Mô hình ngôn ngữ có thể dự đoán khá chính xác xuất của từ tiếp theo trong câu trong đa số các trường hợp. Tuy nhiên, trong một số trường hợp khác, xác suất có thể không chính xác vì mô hình chưa học được tất cả các tình huống và cấu trúc câu có thể xảy ra trong ngôn ngữ tự nhiên. Do đó, việc đánh giá chính xác của mô hình ngôn ngữ luôn phụ thuộc vào tập dữ liệu huấn luyện và tình huống sử dụng.
Các mô hình ngôn ngữ hiện nay (bao gồm cả GPT) đa số đều sử dụng kiến trúc Transformers làm nền tảng cho mạng nơ-ron nhân tạo. Ta sẽ không bàn sâu về Transformers nhưng chỉ cần nắm được rằng Transformers là bước đột phát lớn nhất về kiến trúc mạng nơ-ron trong hơn 10 năm trở lại đây trong mảng xử lý ngôn ngữ tự nhiên. Sự ra đời của Transformers giúp các nhà khoa học huấn luyện được những mô hình rất lớn mà trước đó chưa từng ai có thể nghĩ tới.
Unsupervised Learning From Large Datasets
Một điều quan trọng khác làm nên thành công của mô hình ngôn ngữ đó là phương pháp học không giám sát từ tập dữ liệu lớn và phi cấu trúc. Với các công nghệ AI truyền thống thì các thuật toán học không giám sát vẫn còn chưa phổ biến. Tuy nhiên với mô hình ngôn ngữ thì unsupervised learning đã trở thành một tiêu chuẩn. Hầu hết tất cả các mô hình ngôn ngữ lớn đều được huấn luyện không giám sát. Nhờ vậy công việc gán nhãn dữ liệu được giảm tải đi rất nhiều. Phương pháp này cho phép mô hình học cấu trúc và từ vựng của ngôn ngữ tự nhiên một cách chính xác và tự động. Nó cũng cho phép mô hình tự chỉnh sửa và cải thiện mình mỗi khi nhận được dữ liệu mới. Điều này làm cho mô hình cải thiện liên tục và trở nên rất hiệu quả. Đối với mô hình GPT-3 mới nhất thì nó được huấn luyện trên 570GB dữ liệu văn bản ở tất cả các lĩnh vực được trích xuất từ internet, sách và báo chí.
Transfer Learning
Tiếp theo là vấn đề tài nguyên tính toán. Chúng ta có thể chi hàng chục triệu đô la để huấn luyện mô hình, nhưng để vận hành những mô hình như hàng trăm tỷ tham số như vậy cũng không phải là đơn giản, đặc biệt nhất là chí phí phần cứng. May thay chúng ta cũng có một vài phương pháp để khắc phục vấn đề này, và nổi bật nhất trong số đó là transfer learning và knowledge distillation.
Transfer learning là một kỹ thuật trong học máy cho phép sử dụng một mô hình đã được huấn luyện cho một tác vụ nào đó để giải quyết một tác vụ mới. Điều này giúp giảm thời gian huấn luyện và tăng hiệu quả cho mô hình mới. Nói nôm na là ta có thể chuyển giao tri thức từ mô hình này thông qua mô hình khác mà không cần phải huấn luyện lại từ đầu.
Knowledge distillation là một kỹ thuật thuộc nhóm transfer learning cho phép mô hình nhỏ hơn học tập từ một mô hình lớn hơn. Mô hình nhỏ hơn sẽ sử dụng kết quả của mô hình lớn hơn để dự đoán mục tiêu và sau đó được huấn luyện với tập dữ liệu nhỏ hơn. Kỹ thuật này giúp giảm kích thước mô hình và tăng tốc độ xử lý nhưng vẫn giữ được độ chính xác tương tự của mô hình lớn hơn. ChatGPT đã sử dụng kỹ thuật này để tinh chỉnh mô hình của mình.
Reinforcement Learning From Human Feedback
Như chúng ta có thể thấy, việc học tự động từ dữ liệu lớn giúp mô hình ngôn ngữ có được một "kiến thức" tuyệt vời để trả lời hầu hết mọi câu hỏi của người dùng. Tuy nhiên, do dữ liệu quá lớn và không thể kiểm soát chất lượng của dữ liệu nên mô hình cũng có thể sẽ học được những kiến thức, thông tin sai lệch (vốn tồn tại rất nhiều trên internet và tài liệu). Trước ChatGPT, đã có rất nhiều mô hình AI khác nhận một kết cục không mấy tốt đẹp khi đưa ra những thông tin không phù hợp. Nổi tiếng nhất có lẽ là trường hợp của Tay (Microsoft, 2016) khi đã "kết thúc sự nghiệp" của mình chỉ trong vòng 24 giờ sau khi được release trên Twitter bởi vì đã có những phát ngôn độc hại (https://www.cbsnews.com/news/microsoft-shuts-down-ai-chatbot-after-it-turned-into-racist-nazi/).
Để khắc phục hạn chế này, các kỹ sư của OpenAI đã sử dụng phương pháp Reinforcement Learning From Human Feedback (RLHF - Học tăng cường từ phản hồi của con người). Phương pháp này gồm 3 bước như sau:
- Đầu tiên OpenAI lập ra một team để gán nhãn dữ liệu. Team này sẽ tạo một bộ dữ liệu tiêu chuẩn cho câu hỏi và câu trả lời bao phủ rất nhiều chủ đề khác nhau. Đây được xem là dữ liệu vàng (gold) vì được chính con người tạo ra và có quy trình kiểm soát chất lượng gắt gao. Sau đó, mô hình GPT-3 sẽ được tinh chỉnh (fine-tune) trên tập dữ liệu vàng này. Bây giờ, ta hãy giả sử mô hình được tinh chỉnh kia có tên là InstructGPT.
- Bước tiếp theo, team này có nhiệm vụ là xếp hạng câu trả lời mới của mô hình InstructGPT đã tinh chỉnh. Câu trả lời nào đúng và đủ sẽ được điểm cao, và ngược lại. Từ đó ta có một tập dữ liệu mới đó là tập dữ liệu xếp hạng câu trả lời của mô hình InstructGPT. Sử dụng dữ liệu này ta lại huấn luyện được mô hình khác đó là mô hình xếp hạng câu trả lời (ranking model).
- Đến bước cuối cùng, các kỹ sư sử dụng ranking model đã huấn luyện ở bước trước làm reward model cho bài toán học tăng cường (reinforcement learning) với mô hình InstructGPT là tác tử (agent). Lúc này mô hình InstructGPT đã có khả năng tự học được cách trả lời chính xác các câu hỏi dựa vào reward model mà không cần bất kỳ can thiệp nào của team gán nhãn dữ liệu nữa.

Phương pháp này là "một mũi tên bắn trúng hai con nhạn", vừa giúp giảm kích thước mô hình (distillation) vừa giúp mô hình học được chính xác cách trả lời mà con người mong muốn (alignment).
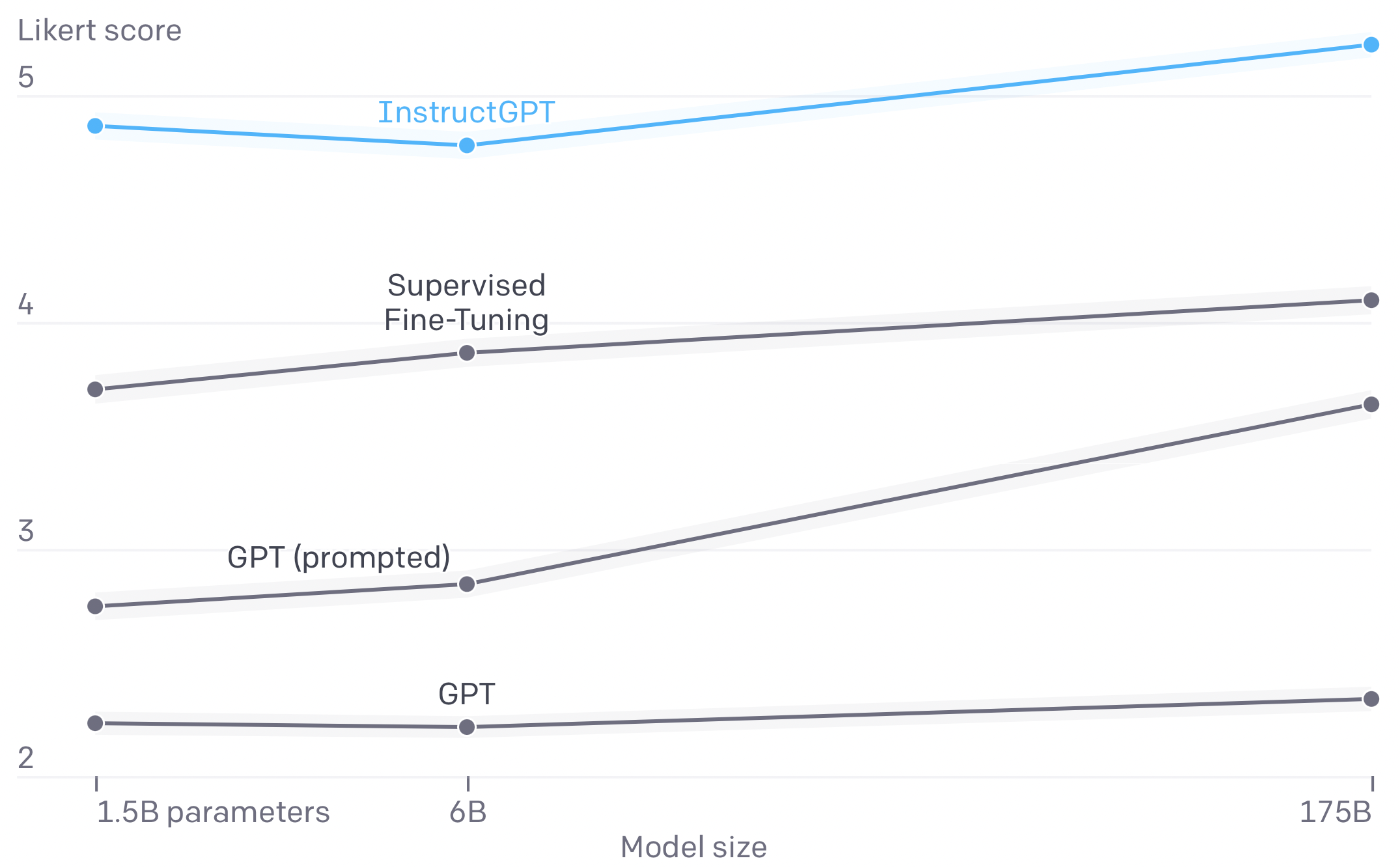
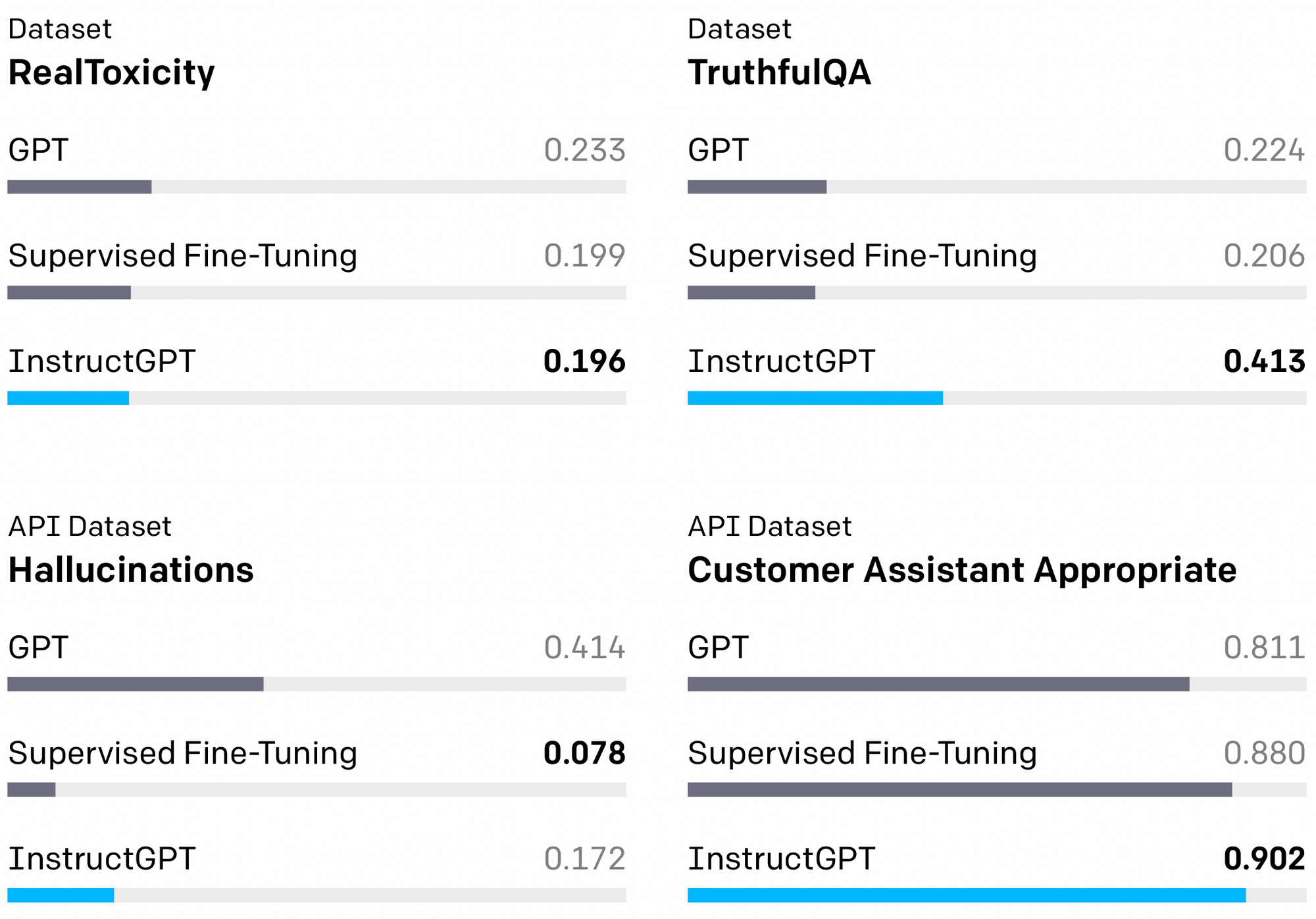
Hạn chế
- ChatGPT đôi khi đưa ra những câu trả lời nghe có vẻ hay nhưng không chính xác hoặc hoàn toàn vô nghĩa trong một số ngữ cảnh. Bởi vì trong quá trình huấn luyện với RLHF, reward model không thể nào cover được hết tất cả các trường hợp, các chủ đề mà ta có.
- ChatGPT khá nhạy cảm với các cụm từ (phrasing), đôi khi một điều chỉnh nhỏ trong câu hỏi hay cụm từ quan trọng cũng có thể khiến mô hình đưa ra các câu trả lời hoàn toàn khác biệt.
- Mô hình khá lạm dụng và dài dòng về cách trả lời câu hỏi, giống như người Việt khi đi thi IELTS :) Điều này có vẻ là do đội ngũ gán nhãn dữ liệu ban đầu thích những câu trả lời như vậy nên dữ liệu họ tạo ra cũng có văn phong giống như vậy.
- ChatGPT không có khả năng cập nhật và trích xuất dữ liệu thời gian thực hay từ những nguồn bên ngoài. Đây là một hạn chế lớn cần phải khắc phục nếu muốn những mô hình như ChatGPT có thể so kè sòng phẳng với các search engine. Tuy nhiên, có vẻ vấn đề này sắp được khắc phục với các dự án mã nguồn mở tương tự như Open Assistant: https://github.com/LAION-AI/Open-Assistant
Kết
Gần đây, phát biểu của Yann LeCun (one of the Godfather of Deep Learning, Chief of AI @ Meta) đã gây ra tranh cãi khá lớn trong cộng đồng khi ông cho rằng ChatGPT không phải là một bước đột phá gì lớn và cũng chẳng phải phát minh của riêng một phòng lab nào (ám chỉ OpenAI). Đúng vậy, về mặt công nghệ thì ChatGPT có thể nói là chẳng có gì đột phá và to lớn như cách truyền thông đang nói về nó. Tuy nhiên về mặt sản phẩm thì ChatGPT đang làm rất tốt. Những ông lớn như Meta, Google không thiếu nhân tài và không thiếu các mô hình AI như vậy, nhưng quyết định đưa nó tiếp cận với công chúng như thế nào mới là điều quan trọng. Có thể thấy Microsoft đã đi những bước rất dài và chiếm lợi thế lớn trong cuộc đua này, quyết định đầu tư đúng đắn vào Github và OpenAI đã mang về một số thành quả nhất định. Ngay sau khi những phiên bản đầu tiên của GPT được release thì Github đã cho ra Copilot - một code completion engine rất hữu ích và tạo ra hiệu ứng truyền thông cũng khá tốt. Trong khi đó, Google Deepmind cũng có mô hình AlphaCode được cho là tốt hơn rất nhiều so với GPT trong việc viết mã nhưng cho đến giờ chúng ta vẫn chưa thấy được sản phẩm nào từ mô hình này. Mặt khác, trước khi ChatGPT xuất hiện thì từ rất lâu Google đã giới thiệu dự án Lambda - một conversation AI gần giống như ChatGPT, nhưng đến giờ cũng vẫn chưa thấy kết quả gì đáng kể từ dự án này. Gần đây, để đối phó với ChatGPT, Google cũng đã công bố báo động đỏ và đưa ra một dự án mới được cho là được nghiên cứu kỹ hơn và đưa ra thông tin trung thực, chính xác hơn ChatGPT. Tuy nhiên cuộc chiến với ChatGPT cũng không có lợi gì mấy cho mô hình bán quảng cáo hiện tại của Google. Google sẽ phải thay đổi ra sao khi với các công cụ như ChatGPT, người dùng sẽ không còn muốn phải lướt qua từng kết quả tìm kiếm như trước nữa, họ sẽ không muốn phải mất thời gian bấm vào những kết quả tìm kiếm nữa. Còn đối với Meta thì lại là một câu chuyện khác. Thời gian đầu, Meta có thể coi là gã khổng lồ tiên phong trong phát triển AI với những thành tựu về thị giác máy tính (ResNet, Detectron,..) và nền tảng PyTorch. Tuy nhiên, Meta đang chậm lại do họ phải đối mặt với rất nhiều vấn đề sống còn khác từ cuộc chiến về quyền tư đến sự cạnh tranh khóc liệt của các mạng xã hội như Tiktok, Twitter,.. Trong bối cảnh đó, thay vì tập trung vào AI, Meta lại đổ nguồn lực vào một "thế giới mới" (metaverse trên nền tảng AR/VR). Nhưng ai cũng có thể thấy, hiện tại thì "thế giới mới" của Meta đang thất bại ê chề.
Ngoài việc theo dõi cuộc chiến của các ông lớn thì chúng ta cũng nên chú ý đến những nỗ lực của cộng đồng mã nguồn mở. Các dự án như transformers-huggingface, BigScience, Open Assistant, Stable Diffusion và rất nhiều dự án khác rất đáng được quan tâm.
Cuối cùng, ChatGPT chỉ là một mô hình ngôn ngữ lớn với mức độ hoàn thiện sản phẩm khá tốt và chiến lược tiếp cận công chúng tuyệt vời. Nhưng con đường từ mô hình ngôn ngữ đến AGI (artificial general intelligence) vẫn còn rất rất xa. Dù vậy, đây chính là lúc chúng ta cần thiết phải có nhìn nhận rõ ràng về sự thay đổi mà AI sắp mang đến, và một nhìn nhận quan trọng hơn đó là công nghệ đang phát triển với tốc độ không thể dự đoán trước. Chúng ta luôn luôn phải sẵn sàng với những bước phát triển đó.


Comments ()