State Of LLM In 2023: A Quick Recap On Latest Advancements

Okay, it's been more than a year since ChatGPT was released. Before this turning point, the research community and industry leaders were already actively working on generative AI, particularly in the realm of computer vision, with a series of stable diffusion findings and applications. To summarize briefly, 2022 could be considered the year of stable diffusion, and 2023 the year of large language models (LLMs).
The beginning of 2023 marked the dominance of LLMs, with ChatGPT leading the charge in widespread adoption and innovation. This year saw LLMs becoming pervasive across various sectors, effectively bridging the gap between theoretical research and practical industry applications. Let's explore the key milestones and trends that shaped the LLM landscape in 2023, also have some insight into how they have revolutionized our interaction with technology.
Year of Open-source LLM
In 2023, we witnessed a remarkable year for open-source large language models (LLMs). The most significant release was the LLaMa series by Meta, setting a precedent for frequent releases thereafter, with new models emerging every month, week, and sometimes daily. Key players like Meta, EleutherAI, MosaicML, TIIUAE, and StabilityAI introduced a variety of models trained on public datasets, catering to diverse needs within the AI community. The majority of these models were decoder-only Transformers, continuing the trend established by ChatGPT. Here are some of the most noteworthy models released this year:
- LLaMa by Meta: The LLaMa family features models of various sizes, with the largest model boasting 65 billion parameters, trained on 1.4 trillion tokens. Notably, the smaller models, especially the one with 13 billion parameters, trained on 1 trillion tokens, demonstrated superior performance by leveraging extended training periods on more data, even surpassing larger models in some benchmarks. The 13B LLaMa model outperformed GPT-3 in most benchmarks, and the largest model set new state-of-the-art performance benchmarks upon its release.
- Pythia by Eleuther AI: Pythia comprises a suite of 16 models with 154 partially trained checkpoints, designed to facilitate controlled scientific research on openly accessible and transparently trained LLMs. This series greatly aids researchers by providing detailed papers and a comprehensive codebase for training LLMs.
- MPT by MosaicML and Falcon series by TIIUAE: Both were trained on a diverse range of data sources, from 1T to 1.5T tokens, and produced versions with 7B and 30B parameters. Notably, later in the year, TIIUAE released a 180B model, the largest open-source model to date.
- Mistral, Phi and Orca: These models highlight another trend in 2023, focusing on training smaller and more efficient models suitable for limited hardware and budget constraints, marking a significant shift towards accessibility and practicality in AI model development.
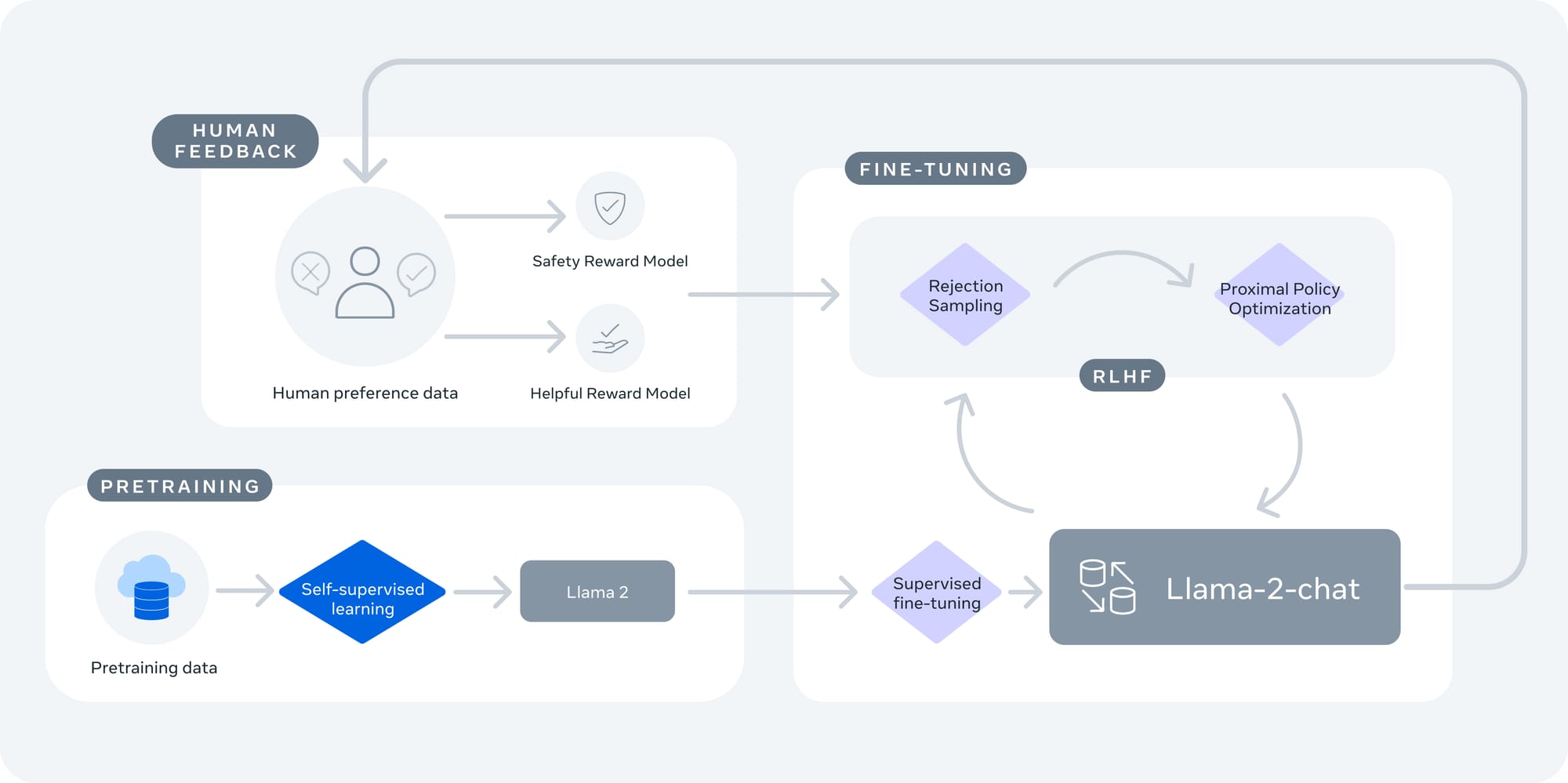
Small and Efficient Model
In 2023, we have also witnessed the release of numerous small and efficient models. The primary reason for this trend is the prohibitively high cost of training large models for most research groups. Additionally, large models are often unsuitable for many real-world applications due to their expensive training and deployment costs, as well as their significant memory and computational power requirements. Therefore, small and efficient models have emerged as one of the main trends of the year. As mentioned earlier, the Mistral and Orca series have been key players in this trend. Mistral surprised the community with a 7B model that outperformed its larger counterparts in most benchmarks, while the Phi series is even smaller, with only 1.3B to 2.7B parameters, yet it delivers impressive performance.
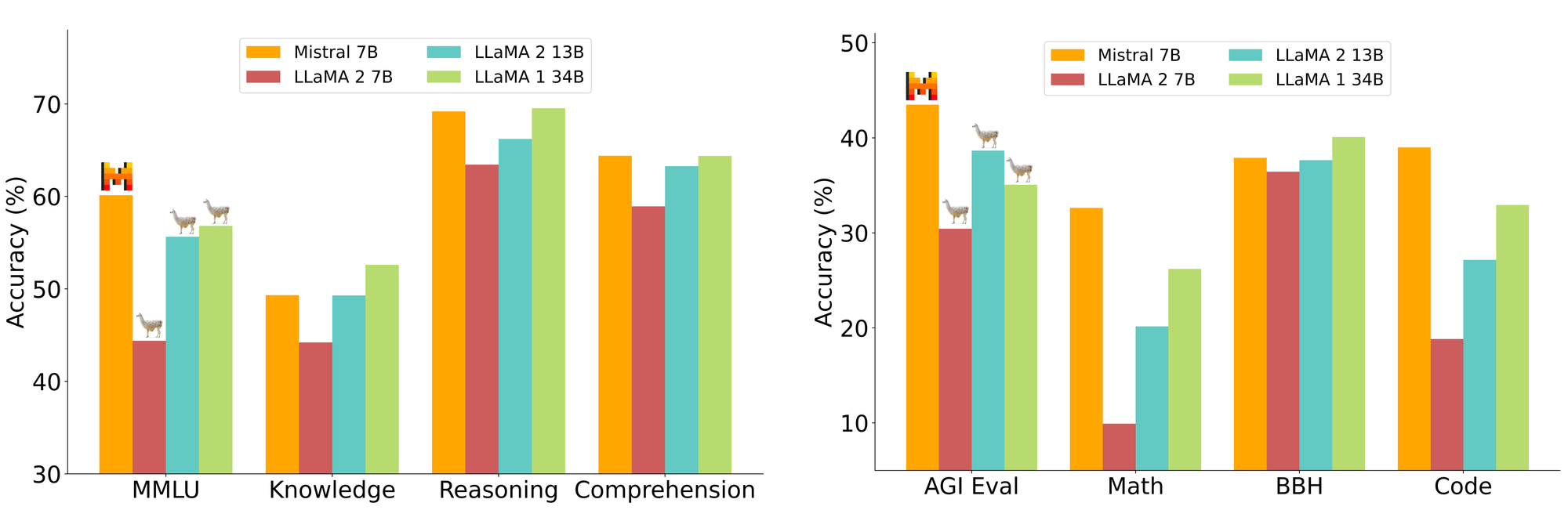
Another innovative approach is Orca 2: Teaching Small Language Models How to Reason, which involves distilling knowledge from a larger model, such as GPT-4, into a smaller one. Unlike previous studies that primarily relied on imitation learning to replicate the outputs of larger models, Orca 2 aims to equip "smaller" LLMs, specifically those with 7B and 13B parameters, with various reasoning methods, such as step-by-step analysis and recall-then-generate techniques. This approach allows these models to identify and apply the most appropriate method for each task, enabling Orca 2 to significantly outperform models of similar size and even compete with models that are 5 to 10 times larger.
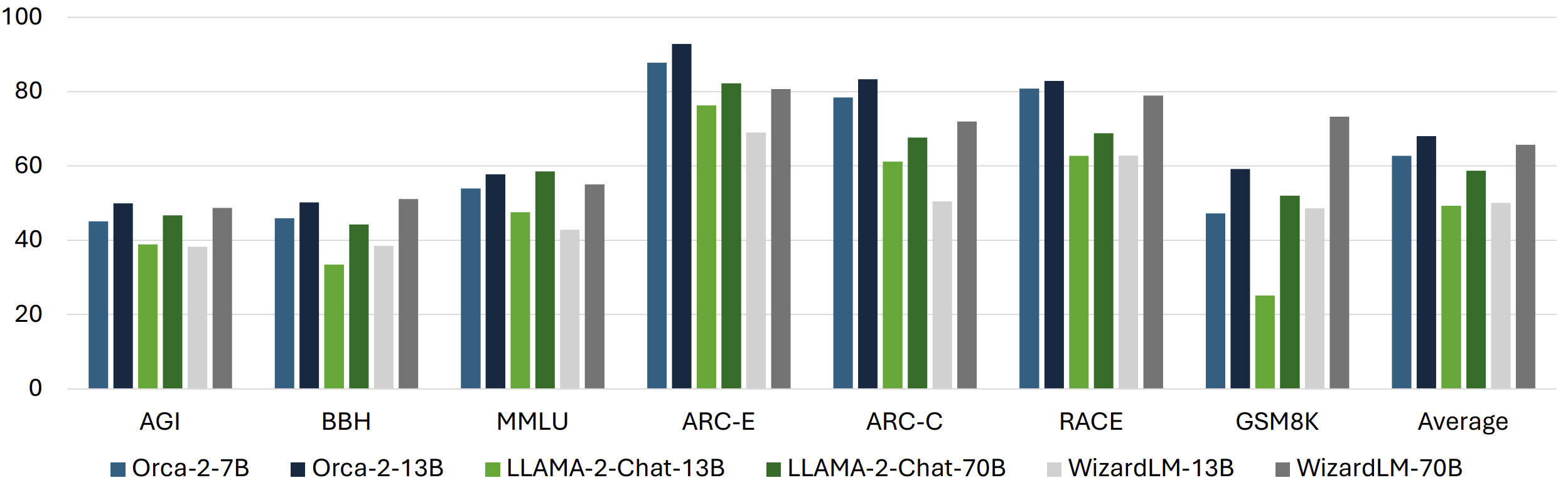
The success of small and efficient models largely depends on data quality and fast attention tricks. While Mistral has not disclosed the specifics of its training data, various research and models have shown that data quality is crucial for training effective models. One of the most notable findings this year is LIMA: "Less Is More for Alignment", which demonstrated that a human-generated, high-quality dataset consisting of only 1,000 training examples can be used for fine-tuning to outperform the same model fine-tuned on 50,000 ChatGPT-generated responses.
Low-Rank Adaption Tuning
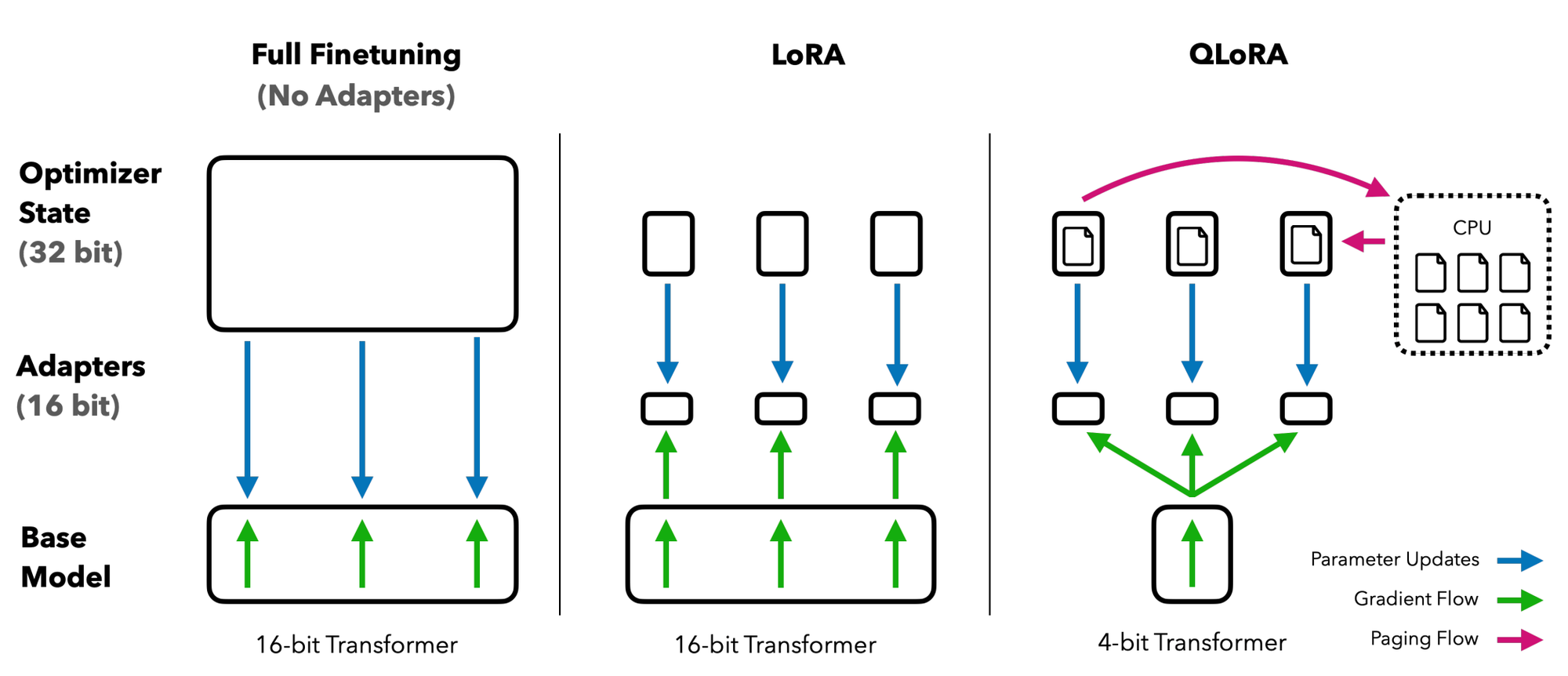
Okay, let's talk about LoRA, which has shone as the brightest star among Parameter-Efficient Fine-tuning methods introduced last year. Low-Rank Adaptation (LoRA) emerged as a game-changer for fine-tuning LLMs efficiently. By introducing low-rank matrices approximation into pre-trained models, LoRA allows for parameter-efficient fine-tuning, significantly reducing the computational load and storage requirements. This approach not only saves resources but also enables customization for different applications without compromising the core capabilities of the base model.
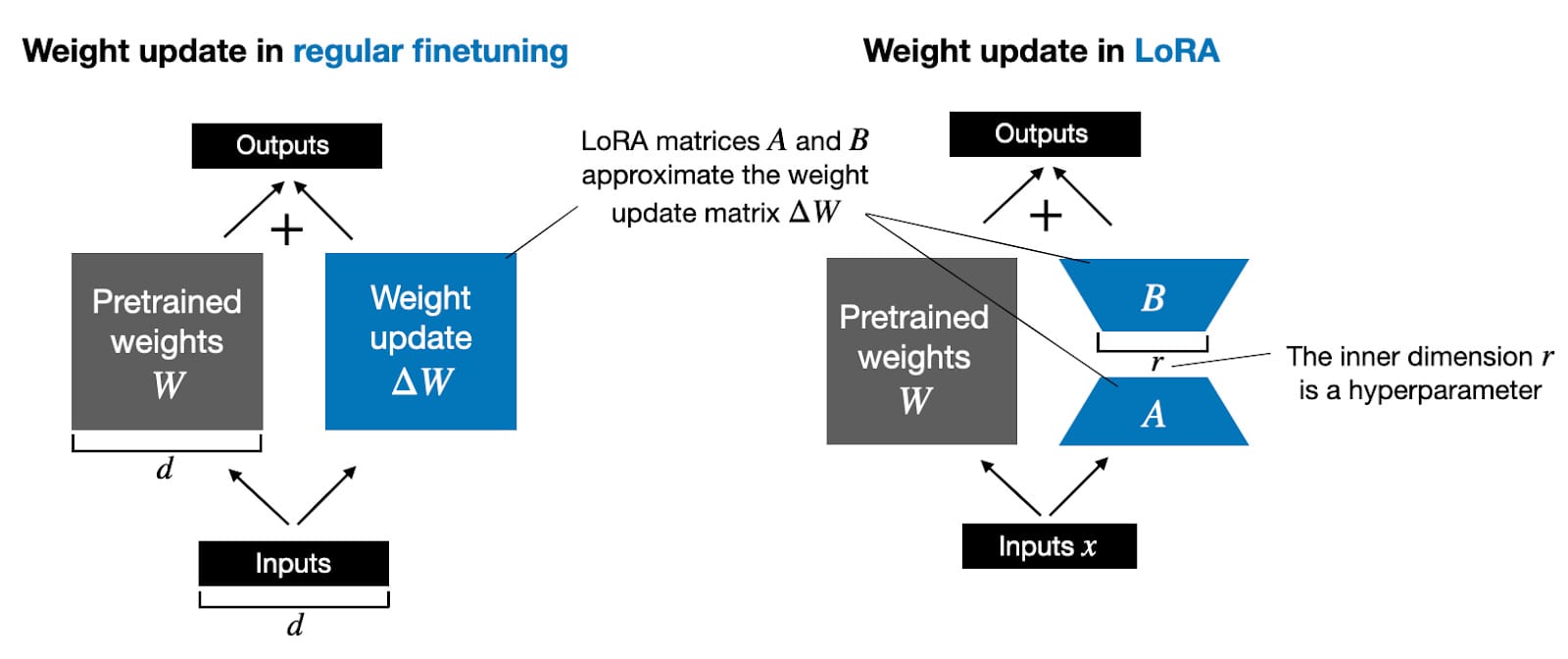
LoRA is basically freeze pre-trained model weights and inject trainable layers (rank-decomposition matrices). These matrices are compact yet capable of approximating the necessary adaptations to the model's behavior, allowing for efficient fine-tuning while maintaining the integrity of the original model's knowledge. One of the most frequently used variant of LoRA is QLoRA (Quantized Low-Rank Adaption). It is the memory efficient version of vanilla LoRA by quantizing the low-rank matrices. This approach allows for the use of low-rank matrices in the fine-tuning process without increasing the memory footprint and less computational-intensive.
Mixture of Experts
The Mixture of Experts (MoE) approach represents a significant leap in LLM architecture last year. MoE is a long-history machine learning paradigm that simplifies complex problems by dividing them into smaller, more manageable sub-problems, each addressed by a specialized sub-model or "expert." This is akin to having a team of specialists, where each member excels in a particular domain. In an MoE model, each expert concentrates on a specific subset of the data or task. The decision of which expert to use for a given input is made by a "gating mechanism," which acts as a traffic director, routing tasks to the most appropriate expert. This method allows MoE models to efficiently and accurately handle a broad spectrum of tasks. MoE is particularly beneficial because it combines the strengths of diverse models, leading to enhanced performance on complex tasks that might be difficult for a single, uniform model to address. It's comparable to having a team of specialists at your disposal, ensuring that every facet of a problem is managed by someone with the requisite expertise, yielding more refined and effective solutions.
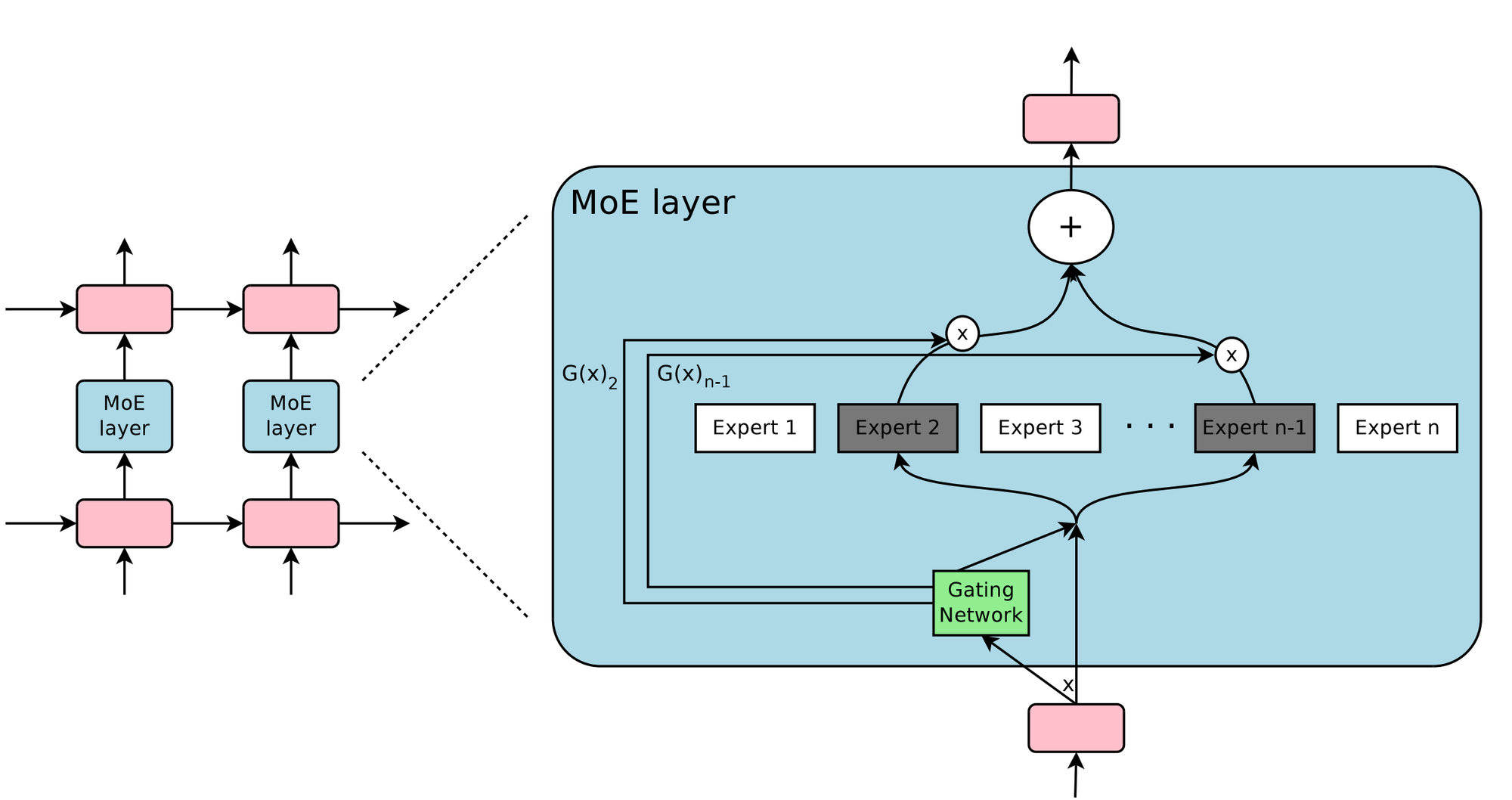
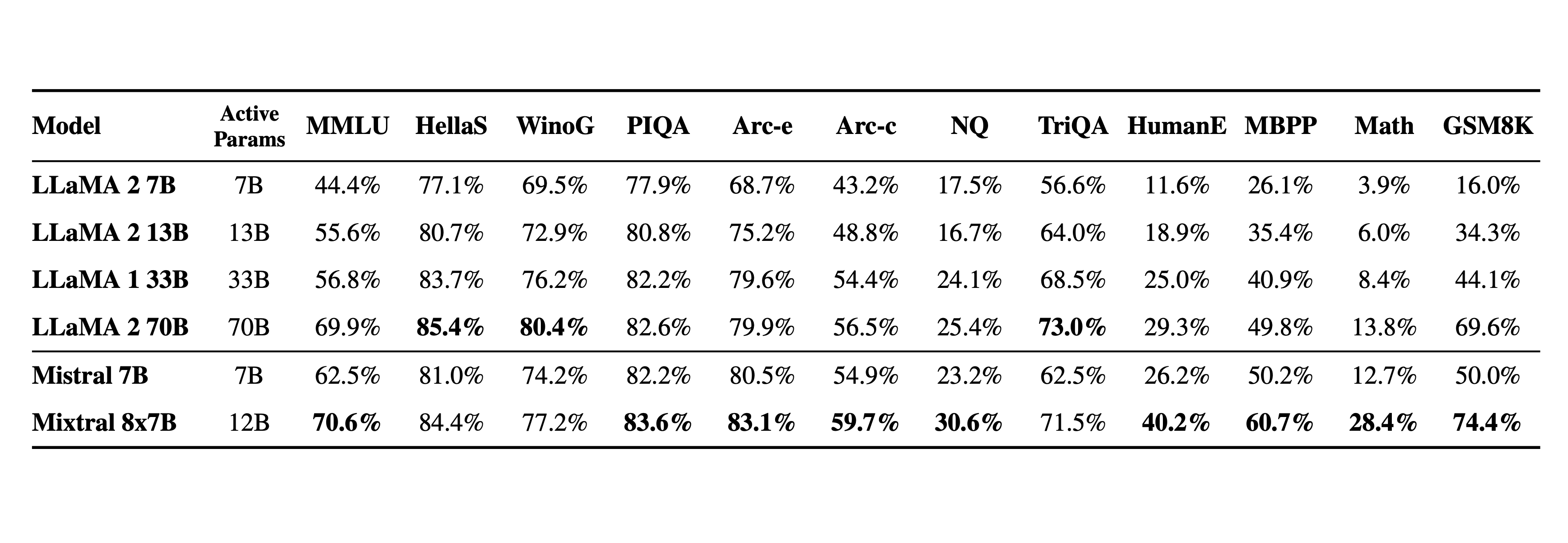
One of the most notable MoE models released last year is Mixtral-8x-7B, which achieved impressive performance by combining eight smaller models, each with 7B parameters, using the MoE approach. There are also rumors that GPT-4 might be an MoE model, consisting of eight expert models, each with 220 billion parameters.
Direct Preference Optimization
Since the introduction of InstructGPT, fine-tuning large language models has become increasingly complex, often relying on the intricate methodology of Reinforcement Learning from Human Feedback (RLHF). Despite its potential, RLHF has been critiqued for its lack of comprehensive documentation, its exploratory and complex nature, and its instability and high resource demands in practical applications. Direct Preference Optimization (DPO) has emerged as a simpler and more efficient alternative to the traditional RLHF, which typically involves training a reward model before optimizing the language model's policy. DPO, on the other hand, bypasses the need for a reward model and directly optimizes the language model using preference data. This method treats the constrained reward maximization problem as a classification task on human preference data, making it a stable, efficient, and computationally lightweight approach. The debate between DPO and RLHF continues, yet DPO has gained notable traction within the open-source community. This preference is evidenced by the increasing number of LLMs that have been fine-tuned using DPO. The method's simplicity and efficiency, compared to the more complex and resource-intensive RLHF, have made DPO an appealing choice for many developers and researchers looking to enhance LLMs. Check out this great post on how to scale DPO to 70B parameters LLMs.
From Language To General Foundation Models
LLMs are evolving into general foundation models, extending their capabilities beyond language processing. This transition signifies a shift towards models that can understand and generate not only text but also code, visual content, audio, and more. Last year, we saw the introduction of models like LLaVA and GPT-4 for vision, which provided impressive capabilities in understanding visual content. This has sparked promising research in the field of general foundation models. In the near future, general foundation models will be able to see, hear, and understand the world around them, enabling more natural and intuitive interactions with humans.
Tool-Equipped Agents
The integration of LLMs with various tools and platforms is making AI more accessible and practical for everyday use. Agents equipped with these tools are being tailored for specific tasks, ranging from coding assistance to creative writing, making AI an indispensable part of many professional workflows. This development has been made possible due to the reasoning and action capabilities of LLMs. This type of feature is often referred to as function calling under the ReAct framework. There are also many models trained on datasets that include function calling to enable this feature. This functionality allows developers to create LLM agents capable of automating a wide range of simple tasks and workflows.

OpenAI Still Dominate Industry Landscape
OpenAI continues to dominate the industry landscape, maintaining its leadership in terms of research and application. The GPT-4 and the new GPT store feature in ChatGPT remain the industry standards, offering high-quality generative AI applications that are unparalleled and unique, with no competitors coming close at this time. OpenAI has also demonstrated significant support for its user community by organizing the first OpenAI Dev Day and providing various developer-friendly features in 2023. Anthropic emerges as one of the most promising competitors, although its flagship LLM, Claude, is not yet widely available. Another tech giant, Google, released Gemini last year, which has been quite impressive compared to OpenAI's GPT series, according to reports. However, it has not yet garnered sufficient traction within the community. We will see what happens in 2024 when they plan to release the largest version of Gemini.

Conclusion
The year 2023 marked a period of significant growth and innovation in the field of large language models (LLMs). From the democratization of AI through open-source models to the development of more efficient and specialized systems, these advancements are not just technical feats but also steps toward making AI more accessible and applicable in various domains. Looking ahead, the potential for these technologies to transform industries and enhance human capabilities continues to be an exciting prospect. In 2024, we anticipate even more remarkable milestones, with Meta announcing plans to train LLaMA-3 and had a plan to open-sourcing it. In the industry landscape, there is also keen interest in seeing whether giants like Google or startups such as Anthropic can surpass OpenAI.
Comments ()