Tổng quan về các phương pháp tổng hợp tiếng nói hiện đại

Tiếng nói phương thức giao tiếp quan trọng nhất của con người. Do đó, đã từ rất lâu các bài toán liên quan đến tổng hợp và mô phỏng tiếng nói luôn được quan tâm một cách sâu sắc. Tuy nhiên, đến những khoảng thời gian gần đây thì bài toán tổng hợp tiếng nói mới có những bước đột phá quan trọng nhờ hoà mình vào dòng chảy của học máy và học sâu hiện đại. Trong nội dung bài viết này, chúng ta cùng nhìn lại bức tranh tổng thể của bài toán tổng hợp tiếng nói hiện đại.
Lược sử phát triển
Tổng hợp tiếng nói (speech synthesis) là bài toán được đặt ra với mục tiêu giúp máy móc có thể mô phỏng lại hệ thống tiếng nói và phát âm của con người, tạo thuận tiện trong giao tiếp giữa người và máy. Thông thường đầu vào của một chương trình hay phần mềm tổng hợp tiếng nói đó là ngôn ngữ dạng văn bản (text) hoặc câu lệnh (command). Còn đầu ra chính là tiếng nói dưới dạng âm thanh. Vì vậy bài toán tổng hợp tiếng nói còn được gọi là bài toán text-to-speech. Một ví dụ rất nổi tiếng cho bài toán toán tổng hợp tiếng nói đó chính là Perfect Paul, công cụ giao tiếp chính của nhà vật lý lỗi lạc Stephen Hawking. Perfect Paul chính là công cụ quý giá đã giúp Stephen Hawking truyền đạt những ý tưởng khoa học của mình đến với mọi người trong gần như suốt quá trình hoạt động khoa học của mình.
Trở lại thế kỉ XVIII, giáo sư Christian Kratzenstein (1723-1795) được ghi nhận là người đầu tiên đưa ra một phương pháp tổng hợp tiếng nói cơ học. Vào năm 1779, ông đã mô tả sự khác biệt khi phát âm các nguyên âm (/u/, /e/, /o/, /a/, /i/) và tạo ra một bộ cộng hưởng âm thanh tương tự như các nhạc cụ với cơ chế rung cho phép tạo ra các âm thanh tương tự như các nguyên âm trên. Không lâu sau, Wolfgang von Kempelen - một nhà khoa học tại Vienna cũng giới thiệu hệ thống mô phỏng tiếng nói đầu tiên của mình với tên gọi Acoustic - Mechanical Speech Machine, AMSM cho phép mô phỏng một số từ đơn và từ ghép không phức tạp. Sau đó cũng có một số nỗ lực cải thiện và nâng cấp AMSM từ nhiều nhà khoa học khác. Về cơ bản, những hệ thống kể trên đều là những hệ thống cơ học. Hệ thống mô phỏng tiếng nói điện tử đầu tiên được phát minh bởi Bell Labs và Home Dubley khi họ đã trình làng hệ thống VODER tại triển lãm New York World's Fair vào năm 1939. Hệ thống tổng hợp tiếng nói bằng máy tính hiện đại đầu tiên cũng được phát triển bởi Bell Labs từ những năm 1950 và hoàn thành vào năm 1968. Năm 1961, giáo sư John Larry Kelly, Jr sử dụng máy tính IBM 704 để chạy chương trình mô phỏng tiếng nói đầu tiên trên máy tính. Đây là một bước ngoặc quan trọng của không chỉ riêng Bell Labs mà là của cả quá trình phát triển của bài toán tổng hợp tiếng nói.

Các phương pháp tổng hợp tiếng nói
Nhìn chung đối với bài toán tổng hợp tiếng nói, ta có thể liệt kê một số nhóm phương pháp như sau:
Articulatory Synthesis (Mô phỏng hệ thống phát âm)
Đây là phương pháp được coi là lý tưởng nhất để giải quyết bài toán tổng hợp tiếng nói. Bởi vì phương pháp này tập trung mô phỏng lại hệ thống phát âm của con người bao gồm sự kết hợp của thanh quản, môi, lưỡi, miệng,.. Tuy nhiên, đây cũng là phương pháp khó thực hiện nhất bởi vì việc mô phỏng lại một hệ thống sinh học phức tạp như hệ thống phát âm của con người là rất khó và tốn nhiều chi phí.
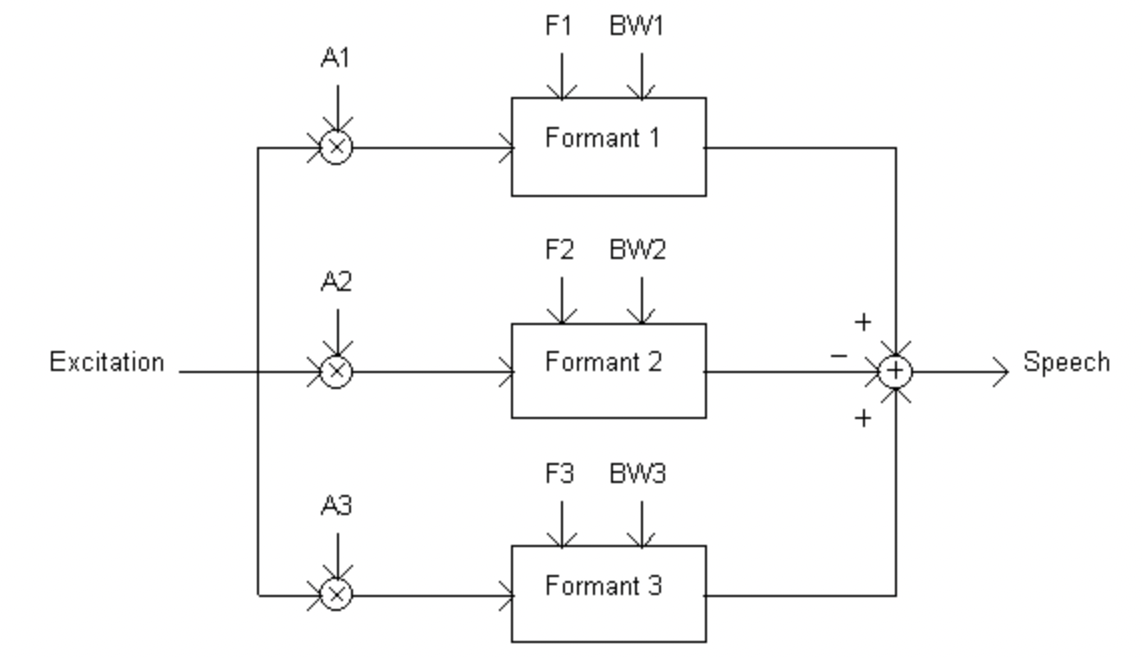
Formant Synthesis (Tổng hợp Formant)
Tổng hợp Formant là một phương pháp sử dụng các quy luật được quy định từ trước để tạo ra âm thanh giống với tiếng nói nhất có thể. Thông thường một bộ tổng hợp formant thường là một hệ thống các bộ lọc (filter) có chức năng khác nhau. Tín hiệu đầu vào thông qua các bộ lộc này sẽ được điều chỉnh cho từng dạng âm thanh nhất định. Ví dụ sẽ có những bộ lộc giúp điều chỉnh âm giai, tần số, và những bộ lộc giúp điều chỉnh âm thanh nhiễu,.. Các bộ lọc này có thể được đặt song song hoặc nối tiếp nhau, hay thậm chí là kết hợp cả hai tuỳ thuộc vào người thiết kế. Nhưng tiếng nói tổng hợp được từ phương pháp này thường thiếu tự nhiên và còn nhiều hạn chế.


Concatenative Synthesis (Tổng hợp ghép nối)
Tổng hợp ghép nói là phương pháp đạt được hiệu quả cao trong một số bài toán cụ thể. Ở phương pháp này, ta sử dụng những tiếng nói đã được thu trước và lưu trữ trong cơ sử dữ liệu dưới dạng key-value. Khi cần sinh tiếng nói, ta chỉ cần chọn ra những âm thanh phù hợp và ghép lại với nhau thành âm thanh hoàn chỉnh. Tuỳ theo cấp độ khác nhau mà chúng ta có thể thực hiện ghép nối từng âm tiết, tiếng, từ, hoặc là cả câu, cả đoạn văn.
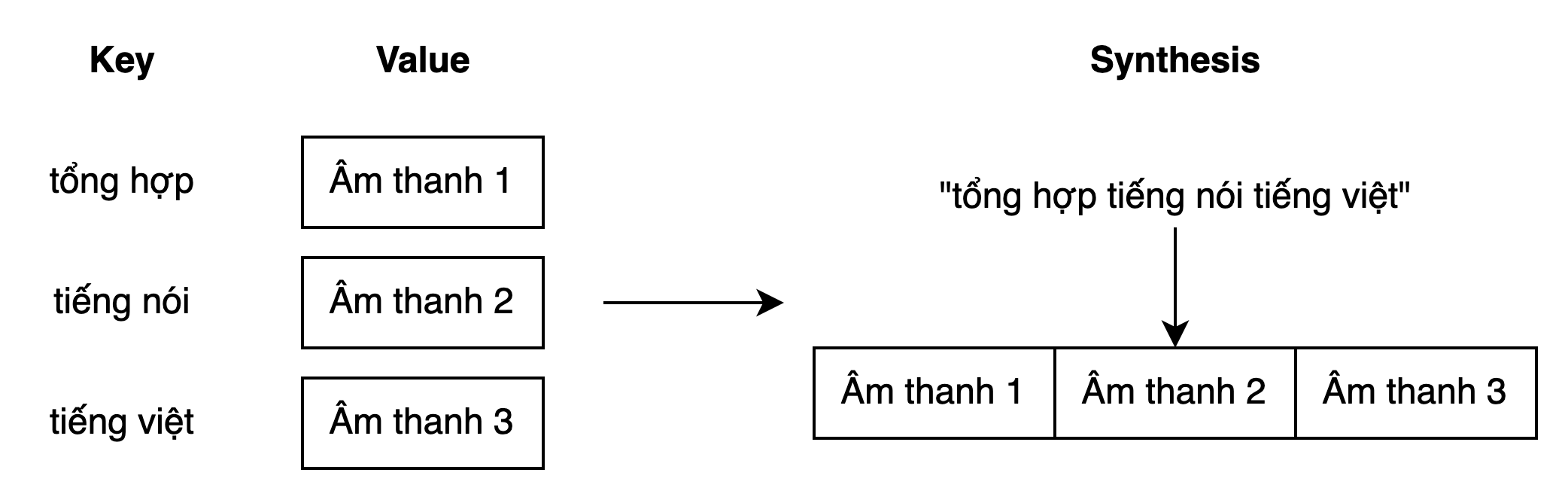
Chúng ta có thể dễ dàng nhận ra công nghệ này được sử dụng ở hầu hết các trung tâm thương mại, nhà ga, sân bay. Ở những nơi đó, người ta sử dụng các đoạn âm thanh đã được thu âm sẵn để thực hiện các thông báo mang tính lập đi lập lại. Đó chính là một ứng dụng của phương pháp tổng hợp ghép nối. Tuy nhiên, điểm yếu rõ ràng nhất của công nghệ này đó chính là rất khó có thể ghép các âm thanh lại với nhau một cách mượt mà ở những cấp độ như âm tiết, tiếng hay từ. Còn đối với cấp độ cả đoạn văn thì phương pháp này chỉ sử dụng được cho các tác vụ nhất định.
Statistical Parametric Synthesis (Các mô hình thống kê)
Để khắc phục những nhược điểm của các mô hình ghép nối, nhiều phương pháp sử dụng học máy thống kế đã ra đời. Ý tưởng chính của nhóm phương pháp này đó chính là thay vì tổng hợp tiếng nói thông qua việc ghép các âm thanh đã thu sẵn lại với nhau thì chúng cố gắng mã hoá các đặc trưng âm thanh (acoustic feature) của văn bản thuần tuý (text). Sau đó dùng những đặc trưng âm thanh này để sinh ra tiếng nói thông qua các thuật toán giãi mã (vocoder). Như nhiều thuật toán học máy khác, các bộ mã hoá (encoder/acoustic model) là những hàm tham số (parametric function) và tham số được ước lượng (học) thông qua một tập dữ liệu có sẵn. Các mô hình tổng hợp tiếng nói dạng này thường có 3 thành phần chủ yếu như sau:

Ở module trích xuất đặc trưng ngôn ngữ, những phương pháp được dùng bao gồm chuẩn hóa (text normalization), tách từ (word segmentation), phân tích cú pháp (syntax analysis),.. Còn đối với mô hình đặc trưng âm thanh thì nổi bật nhất chính là mô hình HMM (Hidden Markov Model). Với module giãi mã (vocoder) thì sẽ bao gồm những thuật toán biến đổi acoustic feature thành âm thanh cuối. Những thuật toán này có mục tiêu là tạo ra tiếng nói tự nhiên, ít nhiễu và cần ít dữ liệu huấn luyện nhất có thể.
Neural Speech Synthesis
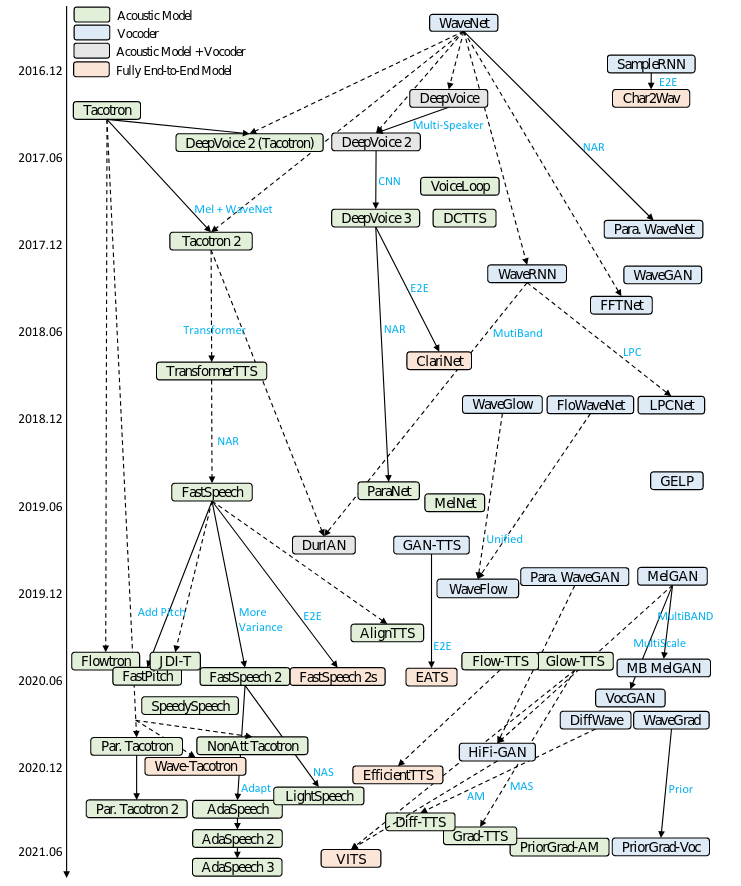
Tuy nhiều phương pháp được nghiên cứu và đề xuất, nhưng sự đột phát trong tổng hợp tiếng nói phải kể đến từ sau những năm 2010. Đó là những năm đầu tiên của cuộc cách mạng học sâu. Một cuộc cách mạng lớn trong khoa học máy tính hiện đại. Tổng hợp tiếng nói là một trong những bài toán được hưởng lợi nhiều nhất từ thành tựu này. Một số nỗ lực đầu tiên trong việc ứng dụng học sâu vào tổng hợp tiếng nói chính là việc sử dụng các mô hình DNN (Deep Neural Network) [c1] và RNN (Recurrent Neural Network) [c2] để thay thế mô hình HMM ở module trích xuất đặc trưng âm thanh.
Các thuật toán Neural Speech Synthesis thường chia làm hai trường phái chính. Thứ nhất đó là giữ nguyên cấu trúc 3 thành phần như các phương pháp statistical parameteric synthesis và thay một vài hoặc toàn bộ các thành phần bằng mạng neuron nhân tạo (neural network). Các mô hình dạng này có thể kể đến như WaveNet [c3], DeepVoice 1-2 [c4]. Trường phái thứ hai là xây dựng mô hình end-to-end (từ đầu đến cuối), các mô hình này tổng hợp âm thanh trực tiếp từ văn bản đầu vào như ClariNet [c5], FastSpeech 2 [c6], EATS [c7]. Ngoài ra một số mô hình như DeepVoice 3 [c8], FastSpeech [c9], Tacotron [c10] là các mô hình end-to-end không hoàn chỉnh. Bởi vì các mô hình này tuy vẫn giữ đủ 3 thành phần nhưng các module như xử lý ngôn ngữ tự nhiên thường được thiết kế đơn giản nhất có thể, và sử dụng mel-spectrogram làm đặc trưng âm thanh chứ không sử dụng một hàm tham số (parametric function) nào cả.
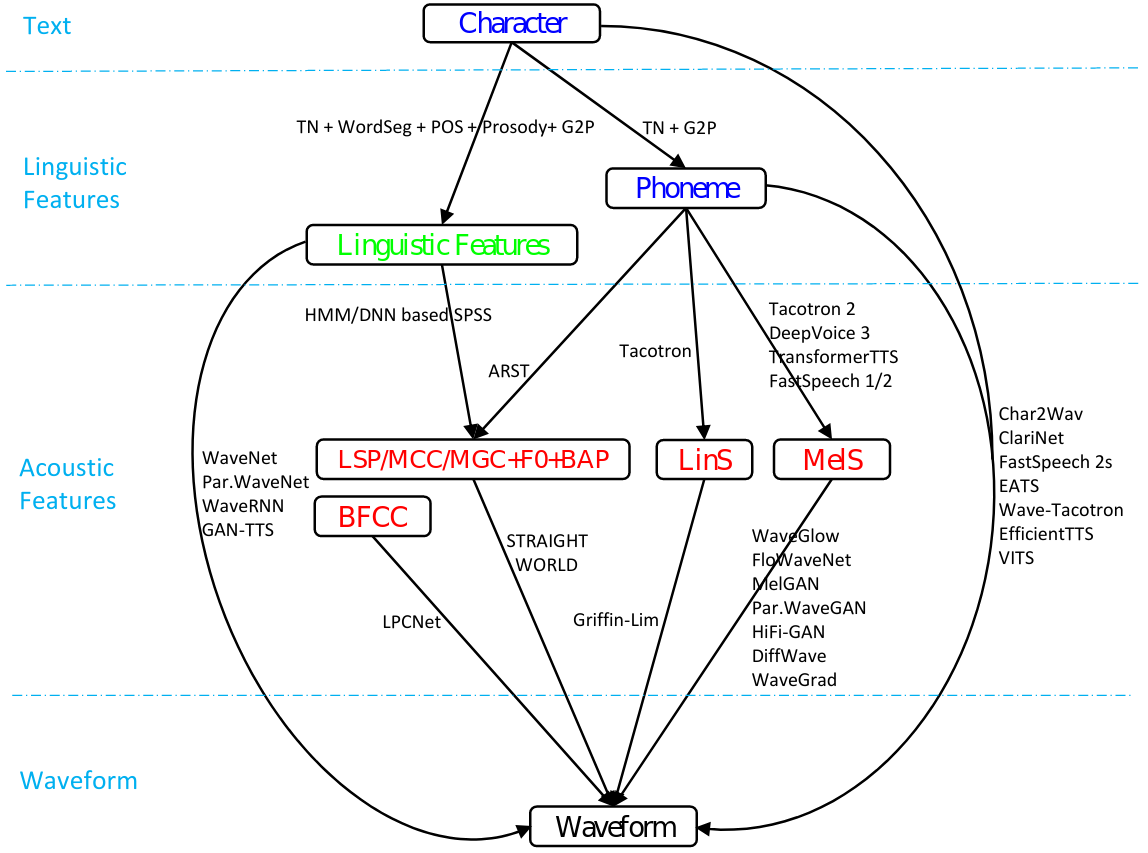
Nhìn chung bước trích xuất đặc trưng ngôn ngữ ở các mô hình tổng hợp tiếng nói hiện đại đều sử dụng những đặc trưng khá cơ bản như part-of-speech, prosody, phoneme,.. Một số mô hình như DeepVoice 1-2 cũng sử dụng character level embedding. Một vài nghiên cứu khác chứng minh việc sử dụng pre-trained language model cải thiện hiệu quả chất lượng mô hình [c8].
Acoustic model chính là phần được tập trung cải thiện nhiều nhất. Cũng như những bài toán sử dụng dữ liệu lớn khác, nhiều mô hình đã được thử nghiệm và đánh giá.
- RNN-based: RNN và các biến thể vốn là các mô hình phổ biến trong các bài toán sequence-to-sequence. Các mô hình Tacotron [c9] đã sử dụng kiến trúc encoder-attention-decoder để mã hóa dữ liệu đầu vào thành linear-spectrogram và dùng Griffin Lim [c10] để chuyển đổi dữ liệu thành âm thanh cuối. Với phiên bản thứ 2 của Tacotron [c11] thì mô hình thay thay thế linear-spectrogram và Griffin Lim thành lần lượt mel-spectrogram và WaveNet [c3] decoder.
- CNN-based: Các mô hình DeepVoice 1-2-3 [c4, c12] sử dụng CNN làm acoustic model và WaveNet làm bộ giãi mã đầu cuối và đạt được nhiều thành công. Ngoài ra ClariNet [c5] và ParaNet [c13] cũng là những mô hình end-to-end CNN dành cho bài toán tổng hợp tiếng nói.
- Transformers-based: Với sức mạnh của cơ chế tự chú ý (self-attention), TransformerTTS [c14] đã sử dụng mô hình Transformer làm acoustic model và đặt được hiệu quả đáng chú ý. Mặc dù khắc phục được 2 nhược điểm cố hữu của các mô hình RNNs là vấn đề phụ thuộc xa (long-term dependency) và không tối ưu được thuật toán huấn luyện song song. Tuy nhiên so với RNNs thì cơ chế self-attention của Transformers chưa tốt bằng cơ chế local-sensitive attention. Do đó một số nghiên cứu tiếp theo đã cố gắng cải thiện cơ chế attention của TransformerTTS như MultiSpeech [c15] và RobuTrans [c16]
- Các mô hình khác: Ngoài những mô hình đã kể trên, nhiều nghiên cứu khác cũng áp dụng các mô hình như GAN và VAE: Parallel WaveNet [c17], WaveGlow [c18], FloWaveNet [c19], Flowtron [c20], FlowTTS [c21], GlowTTS [c22],..
Vocoder
Một thành khác không thể thiếu của bất kỳ mô hình tổng hợp tiếng nói hiện đại nào đó chính là Vocoder. Vocoder (bộ giãi mã) thường là những mô hình/thuật toán nhận dữ liệu đầu vào là đặc trưng âm thanh (acoustic features) đã được trích xuất ở bước trước đó và sinh ra âm thanh cuối ở dạng waveform. Ngoài sử dụng những thuật toán transform như Griffin Lim thì đa số nghiên cứu áp dụng các mô hình neural vocoder là chủ yếu.
- Autoregressive và Non-autoregressive vocoder: Autoregressive model (mô hình tự hồi quy) là dạng neural vocoder phổ biến được sử dụng bởi tính chất liên thuộc ngữ nghĩa trong nội hàm mô hình khi sinh âm thanh. Tuy nhiên các mô hình tự hồi quy gặp khó khăn trong vấn đề song song hoá nên thời gian và chi phí huấn luyện các mô hình này thường rất lớn. Còn những mô hình không tự hồi quy tuy cho ra kết quả chưa tốt như mô hình tự hồi quy nhưng lại khắc phục được điểm yếu kể trên và đang có nhiều bước tiến đáng kể.
- Về kiến trúc mô hình thì tất cả các dạng mô hình sinh từ attention-decoder, GAN [c23], Flow model [c24], VAE [c25], Diffusion model [c26] đều đã được nghiên cứu và đánh giá tỉ mỉ.
Phương pháp đánh giá
Để đánh giá một mô hình tổng hợp tiếng nói là tốt hay không, mô hình này tốt hơn mô hình khác như thế nào vẫn còn là một thách thức lớn. Trong các nghiên cứu, để so sánh phương pháp của mình với phương pháp khác thì người ta dùng dùng thang đo MOS (Mean Opinion Score). MOS được đo bằng cách cho một nhóm những người bản ngữ đánh giá chất lượng giọng nói được sinh ra theo thang điểm từ 1-5 (hoặc có thể khác) và lấy trung bình điểm số. Để so sánh thì người làm nghiên cứu cũng phải hiện thực lại những mô hình khác, trong khi đó không phải nghiên cứu nào cũng có mã nguồn mỡ hay pre-trained model. Hai điều đó khiến cho MOS không thật sự là một thang đo khách quan.
Ứng dụng
Ứng dụng của tổng hợp tiếng nói là nhiều vô số. Có thể kể đến một số như sau:
- Call Center: Hệ thống tổng đài chăm sóc khách hàng.
- Trợ lý ảo: Điều khiển nhà thông minh, lên lịch làm việc, đặt vé xem phim, đặt phòng khách sạn, đọc sách, đọc báo,..
- Hướng dẫn viên: Hướng dẫn viên trong môi trường thực tế ảo (3D, meta-verse,..).
- Robot hỗ trợ người khuyết tật: Ngoài ra tổng hợp tiếng nói có thể giúp hỗ trợ một số trường hợp khuyết tật đặc biệt như khiếm thính. Một nghiên cứu gần đây cho thấy AI đã có thể giãi mã được tín hiệu não người và dự đoán hành vi (AI used to decode brain signals and predict behaviour). Do đó, có lẽ một ngày không xa AI cũng có thể giãi mã tín hiệu mà người khiếm thính muốn truyền đạt bằng công nghệ tổng hợp tiếng nói.
Mặt khác, khi ứng dụng công nghệ tổng hợp tiếng nói thì việc tổng hợp tiếng nói có phong cách là một khía cạnh quan trọng. Ngày nay, đại diện của một thương hiệu không chỉ có phần nhìn mà còn phần nghe. Một tiếng nói có phong cách và đặc trưng riêng cho từng thương hiệu là một nhận dạng thương hiệu quan trọng không kém gì hình ảnh.
Tài liệu tham khảo
[c1] Heiga Zen, Andrew Senior, and Mike Schuster. Statistical parametric speech synthesis using deep neural networks. In 2013 ieee international conference on acoustics, speech and signal processing, pages 7962–7966. IEEE, 2013.
[c1] Yao Qian, Yuchen Fan, Wenping Hu, and Frank K Soong. On the training aspects of deep neural network (dnn) for parametric tts synthesis. In 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3829–3833. IEEE, 2014.
[c2] Yuchen Fan, Yao Qian, Feng-Long Xie, and Frank K Soong. TTS synthesis with bidirectional lstm based recurrent neural networks. In Fifteenth annual conference of the international speech communication association, 2014.
[c2] Heiga Zen. Acoustic modeling in statistical parametric speech synthesis-from hmm to lstm-rnn. 2015.
[c2] Heiga Zen and Ha ̧sim Sak. Unidirectional long short-term memory recurrent neural network with recurrent output layer for low-latency speech synthesis. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4470–4474. IEEE, 2015.
[c3] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
[c4] Sercan Ö Arık, Mike Chrzanowski, Adam Coates, Gregory Diamos, Andrew Gibiansky, Yongguo Kang, Xian Li, John Miller, Andrew Ng, Jonathan Raiman, et al. Deep voice: Real-time neural text-to-speech. InInternational Conference on Machine Learning, pages 195–204. PMLR, 2017.
[c4] Andrew Gibiansky, Sercan Ömer Arik, Gregory Frederick Diamos, John Miller, Kainan Peng, Wei Ping, Jonathan Raiman, and Yanqi Zhou. Deep voice 2: Multi-speaker neural text-to-speech. In NIPS, 2017.
[c5] Wei Ping, Kainan Peng, and Jitong Chen. Clarinet: Parallel wave generation in end-to-end text-to-speech. In International Conference on Learning Representations, 2018.
[c6] Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. Fastspeech 2: Fast and high-quality end-to-end text to speech. In International Conference on Learning Representations, 2021.
[c7] Jeff Donahue, Sander Dieleman, Mikołaj Bi ́nkowski, Erich Elsen, and Karen Simonyan. End-to-end adversarial text-to-speech. In ICLR, 2021.
[c8] Tomoki Hayashi, Shinji Watanabe, Tomoki Toda, Kazuya Takeda, Shubham Toshniwal, and Karen Livescu. Pre-trained text embeddings for enhanced text-to-speech synthesis.Proc. Interspeech 2019, pages 4430–4434, 2019.
[c9] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, et al. Tacotron: Towards end-to-end speech synthesis. Proc. Interspeech 2017, pages 4006–4010, 2017.
[c10] Daniel Griffin and Jae Lim. Signal estimation from modified short-time fourier transform. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(2):236–243, 1984.
[c11] Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4779–4783. IEEE, 2018.
[c12] Wei Ping, Kainan Peng, Andrew Gibiansky, Sercan O Arik, Ajay Kannan, Sharan Narang, Jonathan Raiman, and John Miller. Deep voice 3: 2000-speaker neural text-to-speech. Proc. ICLR, pages 214–217, 2018.
[c13] Kainan Peng, Wei Ping, Zhao Song, and Kexin Zhao. Non-autoregressive neural text-to-speech. In International Conference on Machine Learning, pages 7586–7598. PMLR, 2020.
[c14] Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, and Ming Liu. Neural speech synthesis with transformer network. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6706–6713, 2019.
[c15] Mingjian Chen, Xu Tan, Yi Ren, Jin Xu, Hao Sun, Sheng Zhao, and Tao Qin. Multispeech: Multi-speaker text to speech with transformer. In INTERSPEECH, pages 4024–4028, 2020.
[c16] Naihan Li, Yanqing Liu, Yu Wu, Shujie Liu, Sheng Zhao, and Ming Liu. Robutrans: A robust transformer-based text-to-speech model. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8228–8235, 2020.
[c17] Oord, Aäron van den et al. “Parallel WaveNet: Fast High-Fidelity Speech Synthesis.” ICML (2018).
[c18] Prenger, Ryan J. et al. “Waveglow: A Flow-based Generative Network for Speech Synthesis.” ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2019): 3617-3621.
[c19] Kim, Sungwon et al. “FloWaveNet : A Generative Flow for Raw Audio.” ArXiv abs/1811.02155 (2019): n. pag.
[c20] Valle, Rafael et al. “Flowtron: an Autoregressive Flow-based Generative Network for Text-to-Speech Synthesis.” ArXiv abs/2005.05957 (2021).
[c21] Miao, Chenfeng et al. “Flow-TTS: A Non-Autoregressive Network for Text to Speech Based on Flow.” ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2020): 7209-7213.
[c22] Kim, Jaehyeon et al. “Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search.” ArXiv abs/2005.11129 (2020).
[c23] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33, 2020.
[c24] Wei Ping, Kainan Peng, Kexin Zhao, and Zhao Song. Waveflow: A compact flow-based model for raw audio. In International Conference on Machine Learning, pages 7706–7716. PMLR, 2020.
[c25] Ya-Jie Zhang, Shifeng Pan, Lei He, and Zhen-Hua Ling. Learning latent representations for style control and transfer in end-to-end speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6945– 6949. IEEE, 2019.
[c26] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. arXiv preprint arXiv:2006.11239, 2020.


Comments ()